Natural Language + Von Neumann
This approach is essentially one that looks at the structure of natural language in a statistical way. Other concepts, like CYC start off with an attempt to reason. In fact as can be seen, reasoning ability can be built into this structure.
Proposition - AI research should concentrate on the Internet and large ensembles as this will be the easiest approach
It must be. Consider a AI system operating on a small system. Now we can build that small system into a spider which can then large ensembles. This is true with any system which understands natural language. It is not true necessarily of systems designed to understand the physical world.
Proposition - Bueno espagnol = Turing
Alan Turing did his research just after the second world war, his test said that if you could have a computer which was indistinguishable from a human to a human this was a criterion of AI. Since that time there has been a number of programs constructed and a number of attempts made. "Bueno espagnol" is necessary for consider "mi barco attravesta uns cerradura". The time honored way to beat the test is to produce a sentence that is grammatically correct but nonsense. Above is just such a sentence. If you understand English it is fairly obvious that we replace cerradura with eclusia and that is where we have come from, but that is going "outside the system".
Is it sufficient? This is less clear, however one of the most successful programs was Eliza. This basically was a database responding to user input. If we were to use Google to search for the most appropriate response and then add a blather generator so that we could produce an intelligent and relevant response to every query it is clear that Turing would be passed. Mind the original database would have to be produced by humans.
Proposition - Speech research is an identical problem to language translation.
The same arguments apply about context. There are lots of words with different meanings and spellings which sound the same. Only by prizing out the context can they be distinguished. "Whether, weather", "there, their" etc. The problem of differentiation is exactly the same as for cerradura and eclusia. Indeed you can view it as distinguishing between tiempo and si.or su[s] and aquel[a][s]. In fact speech research is more difficult than natural language translation as there are more ambiguities.
Proposition - A flatpack assembler is a key stage for a Von Neumann system.
If you can understand physical space and laws and perform simple operations, a robot/robotic system can be constructed which repays itself. We know that it is possible to define a series of closed operations. After all basic industry constitutes a set of operations which taken in ensemble are closed.
There is in fact some controversy about how robotic research should be conducted. People are attempting to create cute robots rather than anything with a real understanding of physical space. They say that it "eners our space". To me this is a question of psychology rather than one of cognitive science. I think it is important to keep these two things distinct both in the field of Natural Language and Physics.
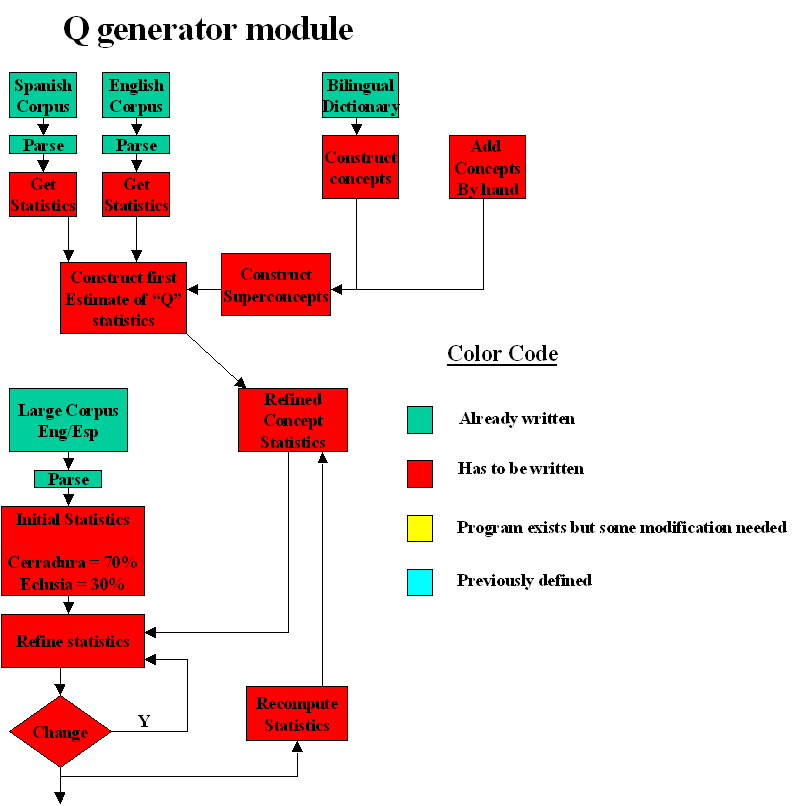
This diagrammatically describes how we can get our first version of Q based on Spanish and English. Other languages can be added at a later date although I think it is clear that once an idea is proved to be viable for a pair of languages it will then start to be applied to many others.
It is also possible to add concepts by hand an produce an initial statistics. As can be seen statistics is produced by taking the statistics of each language and then combining them.
We now have our first version of Q and like the individual languages its statistics are evaluated. A word needs to be said here about superconcepts. A superconcept is a concept which other concepts belong to. Like a duck being a bird. The statistics associated with Q are statistics which relate to concepts and superconcepts.
Writing the basic programs is not in principle complicated. What is complicated is the fact that the statistical data base might be large, consisting of a matrix of probabilities. There is a solution for this Sawzell. A program in Sawzell will look like ant other but it implicitly provides a parallel solution for databases distributed over many computers. It basically runs programs in parallel collating the data on exit so that each program has its own logical track.
There is one further point that can be made is that where we have adjectives associated with nouns we have an insight into the properties of nouns. If we describe nouns as C/Java classes, the possible adjectives will represent the variables.
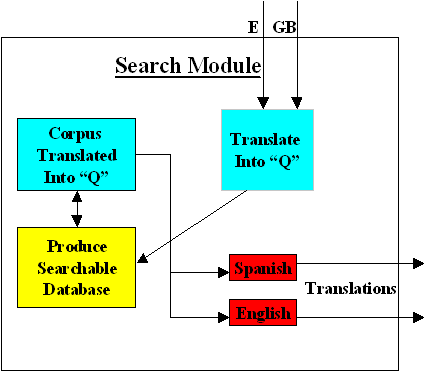
Now if I search for "lock" as Google stands at the moment I get both eclusia and cerradura. These are completely different concepts and are treated differently in "Q". A translation from Q to any natural language is easy as
Q -> NL
is a many one translation and therefore easy. The production of a searchable database is shown in yellow. It is basically standard Google, but some changes may be needed.
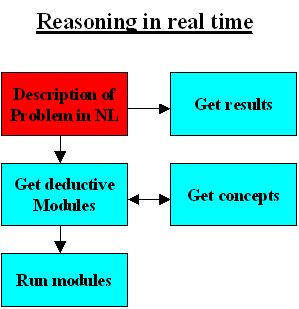
This illustrates perhaps a model of how we actually think The deductive module (see below) is being used We perform deductions, and the results of these deductions may then be used to make further deductions. There is assumed to be more than one deductive module in the system. If you are working with a operating system like Ocean Store which allows for cache trace back, you can make deductions on the fly.
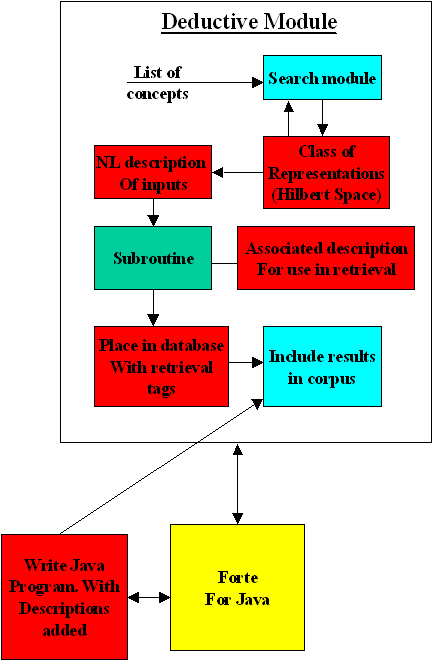
You will notice that there is one yellow box. Forte for Java, Forte is a development system for Java programs which allows you to see the c lasses that are being used.
The idea behind this system is that we have a number of routines which are described in natural language. We use a description of what we want to do. It should be remembered that if we develop programs in a disciplined way the first thing that is done is to describe the purpose of the software. There then follows descriptions at a more and more detailed level. It should be noted in terms of "reusability" that the descriptions can be reused. In the version of Forte envisaged descriptions and what is fished out in terms of the description are shown.
One of the boxes relates to Hilbert Space. This simply means that arguments are often in different forms according to who has written a particular subroutine. A rectangle for example can be described in terms of one of its four corners and the lengths of two sides. Clearly searches will reveal algorithms placed in all forms. The red square is where a description of the Hilbert space is given. This is a description which will enable a Java module to be automatically written which will present the arguments in the form expected by the subroutine. It should be noted that there are packages which will do mathematics in an automated way. They are not much used by mathematicians as, so far, they have not produced any original math. However at this point we are just looking for interfaces to be written, we are not looking for original mathematical thought.

We have a concept and a class associated with the concept. This class variables are defined in natural language as well as in Java. Effectively we are aiming to use the Carnegie Mellon system of levels and what is happening can be described as a documentation standard. The class variables can be readily obtained by looking at the concepts and getting the adjectives associated with the concept/superconcept or by inspection. A "form" - see example given, may be treated as a kind of subset of a class.
Information is extracted from the database by the method shown. At the end of the search process, the concept is populated. Concepts here will generally have superconcepts. For example we have the superconcept of a person and the concept of a particular person. It will readily be seen that this will fill in any form for you. You will of course still have to fill in the pieces of the form which are left indeterminate after the search process.
If you have an operating system - like Ocean Store this could in principle be done by the cache principle. There is a table kept of what depends on a particular piece of information and each program is triggered in the event of change.
In another example if we put in the orbital partakers and observations of asteroids we will get a system which is constantly updated
On the ethical level it can be seen that there are unprecedented levels of personal information. Clearly some attention will need to be given to that.
PHYSICS
Physics stands in contrast to Natural Language Here we are attempting to understand the geometrical world and the world of Engineering Physics.
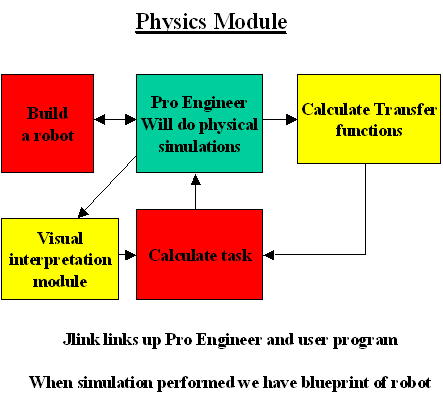
CAD/CAM now involves a very sophisticated set of programs. ProEngineer will do physical simulations and will allow you to write modules in Java which describe the way in which the assembly works. Indeed one can define a word in ProEngineer. ProEngineer enables you to define an environment, such as a house and stairs and will allow the robot to behave in a virtual house along with the control module.
Quite clearly this provides a complete test environment. The transfer functions is calculated from the ProEngineer subroutines which give moments of inertia. When we know transfer functions we can plan our tasks.
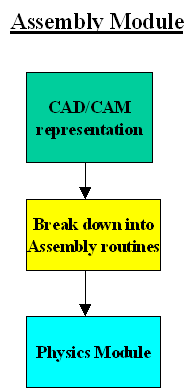
n a CAD package an assembly is broken down into its constituent parts. A robot needs to recognize the various parts/sub assemblies on the ground, pick them up and assemble them again. To do this it needs to understand the physical properties of the parts together with the physical capabilities of the robot(s) itself.

It can be seen how the understanding of the physical world is what enables a robot to perform operations. If a robot understand the physical and the world of CAD/CAM it can perform mechanical tasks in the same way we can. This surely must be the goal of robotic research. This shows the diagram of a multiprocessor robotic system which is self replicating. A Von Neumann machine, or more strictly a Von Neumann swarm.
This serves to show that a robot with any real geometric/physical sense, which does really useful things and isn't just cuddly is a potential Von Neumann system.
posted by Ian Parker at 4:18 AM
5 comments
![]()
![]()

